2009-12-30 Wed
* 更新 - Wikipedia に Google イメージ検索のトップ画像を貼りつける Greasemonkey スクリプト [firefox]
以前 [2007-09-16-1] 作ったGreasemonkeyスクリプトがいつの間にか動かなくなっていた.
Googleイメージ検索のページ構成が変わったのが原因と思われる.イメージ検索結果ページのHTMLから勝手にURLを抜き出すという手抜き実装だったのが問題なので,反省して真面目に Google AJAX Search API (のRESTfulインターフェース) を使って書き直すことにした.
2008-04-23 Wed
* PicLens 対応ウェブサイトの作り方 [firefox][logging] 4 users
Firefox のアドオン PicLens.これはすごい.ぐっと来た.
あまりにぐっと来たので,衝動的にこのサイトでも対応してみた.対応のしかたは以下のページに書いてある.
要は,画像の場所を列挙した Media RSS という XML ファイルを作って, RSS Autodiscovery で見つけさせればよい.うちの Media RSS はこんな感じになった.
Firefox で PicLens をインストール済みの方は,メニューバーの右側
(Firefox の場合) や ボタンバー内 (IE の場合) にある青い矢印ボタンを押してみてください.なんかダーっと写真が流れるはず.
(追記・訂正) すみません,当初 Firefox 専用だと思ってこの記事書いてたのですが,実は IE でも Safari でも動くようです.というわけで一部修正.
2008-04-13 Sun
* Google News の関連記事をまとめて読む Greasemonkey スクリプト [firefox] 12 users
新聞は複数紙を比べながら読みなさいと小学校で習ったわけですが,そういう意味でも Googleニュースの「関連記事」機能はとても便利.しかし,表示された記事を一つずつ開いて読まないといけないのが面倒くさい.なんとかAutoPagerize っぽい感じで一気に読めないものか.
レイアウトもスタイルもバラバラな複数のサイトをまとめて表示することになるので,ページ連結はちと難しそうな感じ.というわけで,やや不本意だけど inline frame を使うことにした.
動作例はこの辺をご覧下さい.
最初は全記事の iframe を一気に展開していたのだけど,冗談かと思うほど重かったので方針変更.ある記事の iframe にマウスポインタを重ねると次のを読み込み始めることにした.ついでなので,はてなブックマークのコメントも展開.はてブ関連のコードははてなブックマークコメントビューワを真似しました.
基本的には,画面の上の方にマウスポインタを置いて,ホイールで下向きにスクロールし続けて行くとそのまま全部読めるはずです.読み飛ばしたいときはポインタをインラインフレームの右か左に外してスクロールさせればよいのですが,読み飛ばしが早過ぎると次のページがまだ読み込まれていなくて逆にイライラする罠.
あ,順番に読まなくても,該当記事の見出しをマウスオーバすればその記事が展開されるようにはなってます.けど読み込み待ち時間がうざいかも.
既知の問題 (というか作ってみてわかった問題):
- iframe のサイズが決め打ち.なんかいい方法ないんですかね.
- ホイール付マウスがないと,かなり使いにくいはずです.本当はキーボードのみでも読めるようにしたい.適当なショートカットキーを設定して iframe にフォーカスできるようにすればよい?
- マウスポインタをピクリとも動かさず,ホイールだけでスクロールして新しい iframe に突入しても,onmouseover は反応しないようです.まあ実際にマウスを使っている場合はピクリとも動かないことはあり得ないのだけど,例えば Let's Note のホイールパッドでクルクルしているとこの問題に当たります.
- まだ割と重い.(単に私のマシンが非力なだけか?)
- ていうかぶっちゃけ iframe うざい.むしろタブをぶわーっと開きまくるようにした方が便利かも?
* [Rosabel] Wow, this is in every rpeesct what I nee... (2013-03-23 11:43:48)
2007-09-16 Sun
* Wikipedia に Google イメージ検索のトップ画像を貼りつける Greasemonkey スクリプト [firefox] 32 users
タイトルのまんまです.Wikipedia で,特に人名とかブラウズしていると,あれ? この人ってどんな顔だっけ,てなことがよくあるので (単に私が老化しただけだともいう) 作ってみた.もちろんちゃんと当人が出て来る保証はない.
- http://www.kagami.org/wikipedia_googleimage/wikipedia_googleimage-0.2.user.js (2009.12.30更新)
-
http://www.kagami.org/wikipedia_googleimage/wikipedia_googleimage-0.1.user.js
スクリーンショット:

あ,いきなりグロいのとかエロいのとか出て来て精神的ダメージを受けても,当方は責任取れませんので覚悟の上でご使用下さい.
[2009-12-30-1] 更新 - Wikipedia に Google イメージ検索のトップ画像を貼りつける Greasemonkey スクリプト
* [Haiqal] Economies are in dire srtaits, but I can... (2012-12-30 09:18:01)
* [かがみ] すみません,Chrome は使っていないのでよくわからないです.どなたか移植して... (2010-09-03 22:33:07)
* [名無しさん] Chromeで入れたところ枠は出るんですが、画像が表示されませんよかったらChr... (2010-08-27 13:12:40)
* [かがみ] コメントありがとうございます.そうですね.その点 Greasemonkey なら... (2007-09-18 02:36:01)
* [ゆきち] これ、ぶっちゃけfair useが使えれば不要な話ですよね...。英語版を見ても... (2007-09-16 15:25:59)
2007-08-02 Thu
* TeX Q & A にナビゲーション用リンクをつける Greasemonkey スクリプト [firefox][texqanavi] 2 users
TeX 関係のトラブルについてウェブで調べていると,高確率で TeX Q & A にたどり着く.
というわけでよく助けられているのだけど,検索エンジン経由で個別の投稿にたどり着いた後,それに対する回答や事の顛末など,後続する投稿をたどって読むのがひと苦労.よくメーリングリストの HTML 化アーカイブにあるような,next by date とか next by thread とかのリンクがあるといいのにな,などと思った.
というわけで,Firefox 限定ですが,「投稿一覧のページの該当箇所に移動するためのリンク」と「関連記事検索結果に移動するためのリンク」を表示する Greasemonkey スクリプトを書いてみたので置いときます:
インストールしてから個別の投稿ページを開くと,タイトルの下の辺りに 2 つのリンクが現れます.
[index page] で投稿一覧ページの該当箇所に移動できます.
[search related articles] で,投稿タイトルで Google 検索した結果のページに移動できます.本当はスレッド表示みたいなのが欲しかったのだけど,簡単にはできそうにないので妥協.
トップページへ移るときの処理がちょっと苦労した.最近の投稿は 500 ごとのアーカイブページ (…/qa/48501-49000.html とか) ではなくてトップページ (…/qa/ 自体) にリストされているので,そっちに移らなくてはならないのだけど,今見ている投稿が「最近のもの」なのかどうかは,そのページだけからは判断できない.結局,HEAD リクエストを余計に送って判断することにしました.
2007-02-17 Sat
* (改版) YouTube にニコニコ動画へのリンクを追加する Greasemonkey スクリプト [firefox][nicovideo] 7 users
(注: この記事は,まだ動画の独自配信をしていなかった頃のニコニコ動画に関するものです.現在のニコニコ動画では以下のスクリプトは動作しませんのでご注意下さい)
勢いで作ったものの [2007-01-28-1],思ったより便利だったので,気に食わなかったところをいくつか修正してみる.
主な変更点は,
- embed されている動画もリンク追加の対象とした
- 同じ動画へのリンクが複数あったときに,片方だけに追加するようにした
- 改行の入れ方をちょっといじった
つまり,YouTube 外のページ (から YouTube へリンクが張られている場合) に適用することを強く意識した改版になっています.これに伴い,図に乗って @include は「*」に変えました.
というわけで,例えばはてなブックマークの「注目の動画」を見るとこうなります.
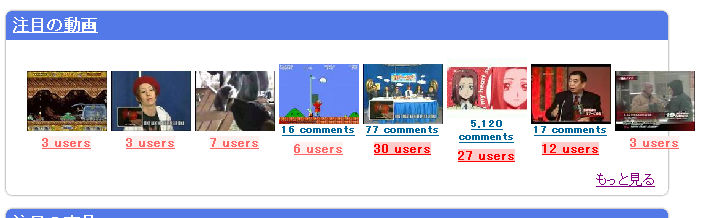
hatenar が注目する動画のうち,どれが vipper に注目されているのかひと目でわかって便利です.たぶん.
[2007-01-28-1] YouTube にニコニコ動画へのリンクを追加する Greasemonkey スクリプト
* [Zaylin] A bit surprised it seems to smilpe and y... (2013-07-04 03:33:56)
2007-01-28 Sun
* YouTube にニコニコ動画へのリンクを追加する Greasemonkey スクリプト [firefox][nicovideo] 6 users
(注: この記事は,まだ動画の独自配信をしていなかった頃のニコニコ動画に関するものです.現在のニコニコ動画では以下のスクリプトは動作しませんのでご注意下さい)
というわけで [2007-01-27-1],YouTubeの動画ページを開いているときに,その動画がニコニコ動画に登録されていたらリンクを表示する Greasemonkey ユーザスクリプトを書いてみた.タイトルとビデオの間あたりに青い文字で表示されます.ほぼ勢いだけで書いていてテストもろくにしてないのでそこんとこよろしくお願いします.
版 → [2007-02-17-1])
Todo かも知れないもの:
- リンクの挿入場所が手抜き.
- 登録の有無の判定が危なっかしい感じ.ニコニコ動画側でAPIを用意してほしいところ.
- AmebaVision って何?
もしかすると,YouTube に張られているあらゆるリンクに対して,ニコニコ動画へのリンクがくっついていると便利なのかも知れないとも思った.誰か改造して下さい.(追記: やってみた.入れ換え済み)
(追記) というわけで勢いついでに YouTube へのリンク全部をがっさりとさらうように変更.デフォルトでは @include を http://*youtube.com/* にしているので YouTube 内のページのみに適用されますが,Manage User Scripts で * に変えれば YouTube 外からのリンクも処理できます.リンク元のページによってはレイアウトが崩れるかもしれないので要注意.というか YouTube の一覧表示でも「Add Video To Quicklist」のボタンとかぶっている時点で既にイマイチ.
(さらに追記) ニコニコ動画の仕様が変わったらしくて動かなくなったので改版.だから早くAPIを(略.ぶつぶつ.
[2007-02-17-1] (改版) YouTube にニコニコ動画へのリンクを追加する Greasemonkey スクリプト
* [Charlesdag] wh0cd183705 <a href=http... (2017-07-06 07:29:09)
2006-11-15 Wed
* Tab Mix Plus のセッション管理を使うのをやめたら Firefox が劇的に軽くなった件 [firefox] 1 user
Firefox を常用している PC が 3 つあるのだけど (自宅デスクトップ,職場デスクトップ,ノート),そのうち 1 つ (職場デスクトップ) だけが妙に動作が重かったり,正常に終了してくれなかったり,メモリをバカ食いするのが直らなかったりして困っていた.で,ふと気づいて Tab Mix Plus のセッション管理機能を使うのをやめたら,さっくり直ったのでその顛末を書いておく.もちろん,一般に言えることなのか,私のところが偶発的におかしくなってただけなのかはよくわかりません.
基本的にセッション保存は Session Saver を使っていたのだけど,ある日 Tab Mix Plus にもセッション保存機能があることを知って,件の PC だけ試しにそっちを使うことにしてみた.
で,その PC がいつの間にか何やら調子が悪い.起動も通常動作も遅いし,メモリは平気で数百 MB 食うし,終了しようとすると決まって「このページのスクリプトは処理に時間がかかっているか応答しなくなっています」とか出て来て「スクリプトを停止」しないとどうにもならなくなったりとか.
こういう流れで書くと,そりゃどう見ても Tab Mix Plus のせいだろと思うのだけど,1 台だけ設定を変えていたことをすっかり忘れていたので,さっぱり原因に思い当たらなかった.
Firefox 2.0 が出て,メモリを食わなくなったと聞いたので,期待しながらアップグレードしてみたのだけど,状況が全く変わらない.こりゃまずいなということで真面目に調査を開始.すると,プロファイルフォルダにある session.rdf なるファイルが 10 MB くらいのサイズになっていることに気づいた.で,このファイルを消して Firefox を再起動してみると,笑っちゃうくらいにサクサク動くようになった.このファイルはどうやら Tab Mix Plus が生成しているらしい (Tab Mix Plus を無効化するとこのファイルは作られないので).というわけで,犯人はこいつだと判断した.
結果,2.0 への移行とも合わせて,Firefox がものすごく快適になりました.この件と,この間知った Scroll with IME [2006-11-03-2] とのおかげで,個人的には Firefox を使わない理由はほぼ完全に無くなったと思った.
あ,公平を期すために(?),Tab Mix Plus のセッション機能が犯人と必ずしも断言できない理由も挙げておこう.
- session.rdf がおかしくなったのは Firefox 1.5 → 2.0 の移行時かも知れない?
- Session Saver と Tab Mix Plus が一緒にインストールされていたからでは? (Session Saver は無効にしていたはずだけど自信がない)
- そもそも使い方が悪いのでは? (10〜20 タブくらい開きっぱなしで,再起動も滅多にしないのが悪いのかも知れない)
つまり session.rdf がおかしかったのはほぼ間違いないと思うのだけど,それが Tab Mix Plus 単体のせいだとは言えないかもしれない,と認識しています.実際,ちょっと調べた範囲だとあまり悪い評判聞かないし.
2006-11-03 Fri
* Scroll With IME [firefox]
IME がアクティブな状態でもスペースキーでスクロールを可能にします。 正確に書くと、IME がアクティブな状態の場合はどの英数キーを押してもスクロールします。 それどころか、半角/全角キーを押すだけでもスクロールします(笑)。
キタコレ!
でも何かときどきおかしくなるような….なんか突然,文字変換候補のウィンドウが現れたりします.滅多にないのでそんなに困ってないですが.
[2006-11-15-1] Tab Mix Plus のセッション管理を使うのをやめたら Firefox が劇的に軽くなった件
2006-10-08 Sun
* (再改版) bloglines のアイテムをまとめて ChangeLog メモに変換する bookmarklet [logging][firefox][bl2clog][bloglines] 2 users
ついで [2006-10-08-2] に bloglines アイテムをクリップボードにコピーする方も改版.こちらは bloglines の変更じゃなくて,Firefox の変更に対する対応になっていると思う.変更箇所は
- setClipboard が,やっぱりフレームの有るページでは動かなくなっているっぽい.以前入れた対策 [2006-04-22-1] を戻した (ていうか今までのも,ソース表示では省略していただけで実は残していた)
- 単に a.firstChild.nodeValue とするだけではタイトルを取りこぼすようになった.以前 [2006-07-05-2] 書いた extractText() を使うことにした.
というわけで以下を bookmark してください.
javascript:(function(){
/*
setClipboard for Firefox
LastModified : 2006-01-10
http://la.ma.la/misc/js/setclipboard.txt
*/
function setClipboard(text){
var url = [
'data:text/html;charset=utf-8;base64,PGJvZHk+PC9ib2',
'R5PjxzY3JpcHQgdHlwZT0idGV4dC9qYXZhc2NyaXB0Ij4KKGZ1',
'bmN0aW9uKGVuY29kZWQpe3ZhciBzd2ZfZGF0YSA9IFsKICdkYX',
'RhOmFwcGxpY2F0aW9uL3gtc2hvY2t3YXZlLWZsYXNoO2Jhc2U2',
'NCxRMWRUQjJ3JywKICdBQUFCNG5EUGdZbGpBd01qSTRNejAlMk',
'YlMkY5JTJGZTJaZkJnYUdhV3dNRE1uNUthJywKICdrTU10TjRH',
'ZGdaZ1NJTXdaWEZKYW01UUFFJTJCQm9iaTFCTG5uTXlDcFB6RW',
'9oU0dJJywKICdQRnAlMkZBeHNEREJRa3BGWkRGUUZGQ2d1eVM4',
'QXlqSTRBRVVCaXkwVndBJTNEJTNEJwpdLmpvaW4oIiIpOwpkb2',
'N1bWVudC5ib2R5LmlubmVySFRNTCA9IFsKICc8ZW1iZWQgc3Jj',
'PSInLHN3Zl9kYXRhLCciICcsCiAnRmxhc2hWYXJzPSJjb2RlPS',
'csZW5jb2RlZCwnIj4nLAogJzwvZW1iZWQ+JwpdLmpvaW4oIiIp',
'Owp9KSgi',btoa(encodeURIComponent(text)+'")</'+'script>')
].join("");
var tmp = document.createElement("div");
tmp.innerHTML = '<iframe src="'+url+'" width="0" height="0"></iframe>';
with(tmp.style){
position ="absolute";
left = "-10px";
top = "-10px";
visibility = "hidden";
};
var b;
try { /* modified by swk */
b = top.frames[0].document.body;
} catch (e) {
b = document.body;
}
b.appendChild(tmp);
setTimeout(function(){b.removeChild(tmp)},1000);
}
function extractText(node) {
var text = '';
if (node.nodeType == 3) { /* TEXT_NODE */
text = node.nodeValue;
} else if (node.hasChildNodes()) {
var n = node.childNodes.length;
for (var i = 0; i < n; i++) {
text = text + extractText(node.childNodes[i]);
}
}
return text;
}
function fmt(title, href) {
return '\r\n\t* ' + title + ':\r\n\t- ' + href + '\r\n';
}
var clog = '';
var h3s = top.basefrm.document.getElementsByTagName("h3");
for (var i = 0; i < h3s.length; i++) {
var a = h3s[i].getElementsByTagName("a")[0];
clog = clog + fmt(extractText(a), a.href);
}
setClipboard(clog);
})();
しかしこう bloglines や Firefox に仕様変更がある度に振り回されるのは何とかならんものか.何か根本的に方針を間違っている気がしないでもないなあ.
[2006-07-08-1] bloglines の keep new をまとめて解除する bookmarklet
[2006-04-22-1] (改版) bloglines のアイテムをまとめて ChangeLog メモに変換する bookmarklet
[2006-02-11-1] bloglines のアイテムをまとめて ChangeLog メモに変換する bookmarklet
2006-09-16 Sat
* Firefox で長いURLを折り返す [tech][logging][firefox][bloglines] 5 users
ソースコードなどを blog などに貼りつけるときにどうするのがよいか,という話がちょっと前に話題になっていたりして,その論点の一つに「横に長すぎる場合」をどう扱うかが挙がっていたりするのだけど,実は似たような問題はほかにもある.連続するASCII 文字列である.
典型的には,長ーい URL 文字列を表示した場合に,枠からはみ出したり,枠自体がびろーんと伸びて見ずらくなったりする.といっても Firefox の場合だけなのだけど.
対策法がこちらによくまとまっている:
ざっくり要約すると,まず Firefox ユーザ側の立場としては,
- Firefox には,連続するASCII文字列を折り返さないというバグがある
- url_breaker という Firefox の拡張機能 (あるいは Greasemonkey スクリプト)があって,このバグを回避できる
一方,Firefox を使っているかどうかに関らず,ウェブサイトの運営側の立場としては,
- 自分のところに来る Firefox ユーザ全員が url_breaker を使ってくれているとは期待できない
- → 実は Greasemonkey 版の url_breaker は,ウェブページ側に仕込んでもうまくはたらくので,それを利用するとよい
ちょっとややこしいのは,url_breaker には「A要素のみを処理するもの」と「全文を処理するもの」という 2 系統があり,さらに「xpi版 (つまり普通の拡張機能)」と「Greasemonkey版」の 2 系統がある,のだが,それらが直交していない.えーと,こんな感じ?
| A要素のみ処理 | 全文を処理 | |
| xpi | url_breakerの Ver.0.2.2以降 | 同左 (オプション設定) |
| Greasemonkey | url_breakerの Ver.0.2.1 | url_breaker_plus |
というわけで,実はしばらく前からウェブページ側に仕込んでみている. url_breaker_plus の方です.各 HTML ファイルの body 要素の一番最後辺りに,
<script src="/js/url_breaker_plus.user.js" type="text/javascript"> </script>
と入れる. url_breaker_plus.user.js はこちら.オリジナルのままだと開き括弧 {, {, [ の直後でも改行しちゃって(個人的に)気持ち悪いので,正規表現を以下のようにちょっと修正して使っている.
// var regexp = new RegExp("([!-%'-/:=\\?@\\[-`\\{-~]|&)");
var regexp = new RegExp("([!-%'\\)-/:=\\?@\\\\-`\\|-~]|&)");
さて,実は長い文字列が横に伸びちゃうのが一番うっとうしいと個人的に思っているのは bloglines なのけど,url_breaker の効果は有ったり無かったりでどうも挙動が謎である.bloglines の記事表示が table レイアウトなのが問題なのかも.
2006-08-16 Wed
* うっかり Flash Player 9 を入れてしまったので 8 に戻す [tech][firefox] 1 user
ふと Flash Player 9 を入れてみたら, Firefox からクリップボードへのコピー ができなくなった.がるる.常用している bookmarklet [2006-07-08-1] が動かなくて困るので, Flash Player 8 に戻すことにする.
この辺を参考にした.
まず 9 をアンインストールした方がよさそうだ.以下のページにある「Flash Player 8 uninstallers」がそのまま使えた.IE とか Firefox を起動したまま走らせるとちょっと厄介だったので,止めてからの方がよさげ.
過去のバージョンの Flash Player は以下のページにある.Flash Player 8 をダウンロード,展開して,インストール.
というわけで無事戻った.
2006-07-08 Sat
* bloglines の keep new をまとめて解除する bookmarklet [logging][firefox][bl2clog][unkeepnew][bloglines]
改版しました [2006-10-08-2]
他人様のコードをいじっているうちに [2006-07-05-2] [2006-07-05-3] 何となく勘がつかめてきたような気がするので,調子に乗って懸案事項に手をつけてみる.
以前,bloglines で表示中の記事のタイトル名,URL をまとめてクリップボードにコピーする bookmarklet (Firefox 専用) を書いた [2006-02-11-1] [2006-04-22-1].これ使うときは,
- 気になった記事をさくさく keep new していく
- 最後にまとめて bookmarklet でクリップボードにコピー
- その後,keep new された記事を 1 個ずつ解除 (← ここがイヤ)
という流れが多くて,何とかならんかなと思ってたのだ.
というわけでこんな感じ.
onload を使っているので MSIE では動作しないはず.直すのは簡単だと思うけど,とりあえず放置.
ソース:
javascript:(function(){
function phandler (paths) {
if (paths.length < 1) {
return;
} else if (paths.length == 1) {
top.treeframe.location = paths[0];
return;
}
var p = paths.shift();
var xhr = new XMLHttpRequest();
xhr.onload = function () { phandler(paths); };
xhr.open('GET', p, true);
xhr.send(null);
}
var paths = new Array;
var ipts = top.basefrm.document.getElementsByTagName("input");
for (var i = 0, k = 0; i < ipts.length; i++) {
if (ipts[i].type == "checkbox"
&& String(ipts[i].onclick).match(/markUnreadItem\(\s*(\d+)\s*,\s*(\d+)\s*\)/)
&& ipts[i].checked == true) {
var subid = RegExp.$1;
var itemid = RegExp.$2;
ipts[i].checked = false;
paths[k++] = '/myblogs_subs?ui=1&subid='+subid+'&itemid='+itemid;
}
}
phandler(paths);
})();
期せずして Ajax デビューしてしまった.(XML 使ってないから Aj デビューか?)
やってることは単純で,keep new のチェックボックスについている onclick 属性から,その記事の subid と itemid を取り出して,それらからパス名 '/myblogs_subs?ui=1&subid='+subid+'&itemid='+itemid を生成して,GET しに行っている.
bloglines で実際に keep new のボタンを押した場合は, parent.treeframe.location にこのパス名を直接代入するコードが実行されるのだけど,複数の記事についてこれを単純に繰り返すと,前のやつの読み込みが終わる前に次のやつを読みに行ってしまってうまく行かない.というわけで XMLHttpRequest を使ってみた.
(open の第3引数を false にすればもっと簡単に書けるかと思ったけど,そうすると解除がすべて終わるまで操作を受け付けなくなってしまって,使いにくかった)
ついでなので,まとめてクリップボードにコピーする方もちょっとだけ書き直しておく.以前のは正規表現で無理矢理抽出してたけど,真面目に DOM ツリーをたどるようにした.
ソース:
javascript:(function(){
function setClipboard(text){
/* 省略 (http://la.ma.la/misc/js/setclipboard.txt) */
}
function fmt(title, href) {
return '\r\n\t* ' + title + ':\r\n\t- ' + href + '\r\n';
}
var clog = '';
var h3s = top.basefrm.document.getElementsByTagName("h3");
for (var i = 0; i < h3s.length; i++) {
var a = h3s[i].getElementsByTagName("a")[0];
clog = clog + fmt(a.firstChild.nodeValue, a.href);
}
setClipboard(clog);
})();
ChangeLogメモ以外の形式に変換したい場合は,fmt() の中身を適当にいじってください.
[2006-10-08-2] (改版) bloglines の keep new をまとめて解除する bookmarklet
[2006-08-16-1] うっかり Flash Player 9 を入れてしまったので 8 に戻す
[2006-08-07-2] なんか bloglines が全然ダメな件
[2006-04-22-1] (改版) bloglines のアイテムをまとめて ChangeLog メモに変換する bookmarklet
[2006-02-11-1] bloglines のアイテムをまとめて ChangeLog メモに変換する bookmarklet
* [Sandroo] An inetlglinet point of view, well expre... (2013-01-01 20:46:17)
2006-07-05 Wed
* HTML の table で,ヘッダを固定にしてデータ部だけスクロール [tech][firefox] 6 users
ソート [2006-07-05-2] に引続き,
行数の多い表の場合,ヘッダ部がスクロールアウトしてしまわないように固定したくなる.
というようなニーズもやっぱり結構あって,実際いろんなところでそういう機能を実現する JavaScript のコードが公開されている.いくつか当たってみた中で,一番気に入ったのはこれ:
気に入った理由は,
- 比較的レイアウトが崩れない
- ブラウザ依存が少ないっぽい (といっても IE と Firefox しか試してないけど)
- 日本語が入ってても崩れない
って要するに崩れないことが重要.他の方の実装も含めて,要するにヘッダ部と本体とを分離して別の table 要素にして,本体だけにスクロールバーをつける,というのが動作原理なので,列幅の再現性をいかに高くするかがポイントになる,のだと思う.ここで紹介されているコードは,(やっぱりちょっとはズレる場合があるのだけど) かなりイケている,と思う.ありがたく使わせて頂いております.
メモその1:
テーブルの height は px 単位で指定するようになっている.画面全体に対するパーセンテージで指定できると便利かな,と思って
newDiv2.style.height = tHeight+'px';
のところを 'px' じゃなくて '%' にしてみたのだけど,doctype スイッチ [2005-11-15-2] に引っかかるようになってしまった.doctype 宣言にシステム識別子がある場合,'px' だとスクロールバーが出るけど '%' だと出ない.システム識別子がなければ,どちらでもスクロールバーが出る.謎.
メモその2:
作者の Mars さんも書いておられますが,このままだと印刷するときちょっと困る (全体が印刷できない).というわけで,かなりアドホックですが,こんな回避策をとってます.
(以下の実装は obsolete → メモその3 へ)
まずグローバルな変数を 2 個用意.
var newDiv2; var myHeight;
Tscroller() の中で newDiv2 をローカル変数として宣言するのをやめて,このグローバル変数を使うことにする.つまり単に
var newDiv2 = document.createElement('div');
を
newDiv2 = document.createElement('div');
にする.それから Tscroller() の中のどこかで
myHeight = tHeight;
してやる.最後に
function ToggleScroll()
{
if (newDiv2.style.height == '') {
newDiv2.style.height = myHeight + 'px';
} else {
newDiv2.style.height = '';
}
}
な関数を定義しておいて,適当な場所から href なり onclick なりで呼べるようにしておく.これでスクロールバーをオン・オフできます.たぶん.
もっときれいに作れる気もするけど,最小の改造でやるならこんなところだろうか.
メモその3 (追記):
メモその2 がちょっとあまりにもアドホックすぎた気がする.テーブル 2 つ以上扱おうとしたらもうダメだし.もうちょっとだけ真面目に書きます.
メモその2 で書いた改造はすべて撤廃,改めて元の Tscroller() の最後あたりに以下を入れて,
newDiv2.height_saved = tHeight;
以下のような関数を定義する.
function ToggleScroll(tid)
{
var newDiv2 = document.getElementById('D_' + tid + '_B');
var tHeight = newDiv2.height_saved;
if (newDiv2.style.height == '') {
newDiv2.style.height = tHeight + 'px';
} else {
newDiv2.style.height = '';
}
}
引数には Tscroller に与えたのと同じく,テーブルの id を渡します.
<a href="javascript:ToggleScroll('tb')">
Click here to toggle the scroller</a>.
div に height_saved なんていうプロパティを勝手に作っているところが非常にうさんくさい.こういうことするのって規格上はダメなんですかね? 一応 IE と Firefox では動いている模様.
[2006-07-08-1] bloglines の keep new をまとめて解除する bookmarklet
* [Maulida] I\'m really into it, tahkns for this gre... (2013-07-04 11:25:50)
2006-07-05 Wed
* HTML の table を sort できるようにする [tech][firefox] 1 user
HTML の表を,列名をクリックしてソートできるようにしたい.
というようなニーズは結構あって,実際いろんなところでそういう機能を実現する JavaScript のコードが公開されている.いくつか当たってみた中で,一番気に入ったのはこれ (の試作5):
気に入った理由は,
- 比較関数やデータ取得関数をパラメータとして渡せるなど,汎用性に気を配った設計になっている
- 速度面にも気を配った設計になっている
という辺り.ありがたく使わせて頂いております.
メモその1:
実際の表は,<td> の中にテキストが直接書かれているとは限らなく,たとえば <a> で囲まれたテキストが書かれてたりとかすることもあるわけで,一般にはテキストに行き着くまで DOM ツリーを再帰的にたどってやる必要がある.データ取得関数 getfn が分離されているので,こんなコードを書いて getfn として渡してやることにした.
function byStrNoCase (cell) {
return extractText(cell).toLowerCase();
}
function byInt (cell) {
return parseInt(extractText(cell));
}
function extractText(node) {
var text = '';
if (node.nodeType == 3) { // TEXT_NODE
text = node.nodeValue;
} else if (node.hasChildNodes()) {
var n = node.childNodes.length;
for (var i = 0; i < n; i++) {
text = text + extractText(node.childNodes[i]);
}
}
return text;
}
メモその2:
JavaScript の Array の sort() は,安定であるとは保証されていないらしい.実際,IE は安定なソートをしてくれているっぽいが Firefox だと安定でない.テーブルをかちかちクリックしてソートしたいときというのは,たとえば計算機一覧を,まずホスト名順にソートして,それから管理者順にソートしてから,自分が管理者になってる子たちを見る,なんていう使い方をすることが多いので,ソートは安定であって欲しい.
一番安直にやるには,ソート対象の要素にプロパティとして元の順番も持たせておいて,比較して引き分けだったら元の順番を保存するような比較関数 cmpfn を渡してやればよい.
のだが,元のコードだと,getfn が返した値を Object 型に変換してそれをソートしているので,比較の結果として引き分けにならない.しかたないので,getfn の返した値を Object 型に変換するのではなく,Object のプロパティとして getfn の返した値を持たせてやるように書き換えて使っている.つまり
for(var i=0; i<N; i++)
x[i] = Object( getfn( rows[i].cells[index] ) ), x[i].row=rows[i];
の部分を
for(var i=0; i<N; i++) {
x[i] = new Object;
x[i].v = getfn(rows[i].cells[index]);
x[i].row = rows[i];
x[i].idx = i;
}
にしてやる.cmpfn は
function cmpAsc(a, b) {
if (a.v == b.v) {
if (a.idx == b.idx) {
return 0; // can't happen
} else if (a.idx > b.idx) {
return 1;
} else {
return -1;
}
} else if (a.v > b.v) {
return 1;
} else {
return -1;
}
}
function cmpDesc(a, b) {
return cmpAsc(b, a);
}
みたいな感じ.
[2006-10-08-3] (再改版) bloglines のアイテムをまとめて ChangeLog メモに変換する bookmarklet
[2006-07-08-1] bloglines の keep new をまとめて解除する bookmarklet
[2006-07-05-3] HTML の table で,ヘッダを固定にしてデータ部だけスクロール
* [Christian] Thanks for the great info dog I owe you ... (2012-12-30 13:35:14)
2006-04-22 Sat
* (改版) bloglines のアイテムをまとめて ChangeLog メモに変換する bookmarklet [logging][firefox][bl2clog][bloglines]
以前公開して [2006-02-11-1],その後 Firefox 1.5.0.1 だと動かないことが判明した [2006-03-08-2] bloglines to ChangeLogMemo な bookmarklet ですが,Firefox が 1.5.0.2 に自動更新されてから試してみたところ,普通に動くことが判明.なんですかこれ.
実はちょうど動かない原因を調査していて,回避策が分かった矢先だった. Firefox のJavaScript コンソールによると,フレームのあるページで document.body.appendChild と document.body.removeChild を呼び出そうとすると
エラー: uncaught exception: [Exception... "Node was not found" code: "8" nsresult: "0x80530008 (NS_ERROR_DOM_NOT_FOUND_ERR)" location: (コード略) Line: 1"]
となっていたらしい.
バグフィクスリストを見ても,とくに該当しそうなものに見当がつかないんだけどな.まいいか.
- http://www.mozilla.com/firefox/releases/1.5.0.2.html
- http://www.squarefree.com/burningedge/releases/1.5.0.2.html
というわけで,Firefox 1.5.0.1 で動かさない限りは動作は変わりませんが,一応新しいの置いておきます.
-
bl2clog→ New [2006-07-08-1]→ しつこくNew [2006-10-08-3]
以前のは,sacja TTT-protokolo さんの bookmarklet が元ネタでしたが,上記の原因調査の過程で,そのさらに元ネタである 最速インターフェース研究会さんの に遡りました.
中身は
javascript:(function(){
function setClipboard(text){
(略)
}
var src = top.frames[1].document.body.innerHTML;
var pat = /<h3><a title=%22.*href=%22(.*)%22 target=%22_blank%22>(.*)<\/a>.*<\/h3>/g;
var clog = '';
var result;
while ((result = pat.exec(src)) != null) {
clog = clog + '\r\n\t* ' + result[2] + ':\r\n\t- ' + result[1] + '\r\n';
};
setClipboard(clog);
})();
setClipboard() の中身は http://la.ma.la/misc/js/setclipboard.txt です.途中の appendChild, removeChild するところをいじってますが,敢えて Firefox 1.5.0.1 で使わない限りはオリジナルのままでよいです.
ChangeLog じゃなくて他のフォーマット変換したいときは clog = clog + ... のあたりを適当に.
[2006-10-08-3] (再改版) bloglines のアイテムをまとめて ChangeLog メモに変換する bookmarklet
[2006-07-08-1] bloglines の keep new をまとめて解除する bookmarklet
[2006-03-08-2] Firefox 1.5.0.1 にしてみたら
[2006-02-11-1] bloglines のアイテムをまとめて ChangeLog メモに変換する bookmarklet
* [Nickey] The expertise shines through. Thanks for... (2012-12-30 17:30:07)
2006-03-08 Wed
* Firefox 1.5.0.1 にしてみたら [tech][firefox]
ふと思い立って Firefox を 1.5.0.1 にしてみた.
はまった点:
- googlebar が対応しなくなった.google toolbar に乗り換え.
- 自作 bookmarklet [2006-02-11-1] が動作しなくなった.がるる.(追記: Firefox 1.5.0.2 なら動く [2006-04-22-1].がるる)
はうー
[2006-04-22-1] (改版) bloglines のアイテムをまとめて ChangeLog メモに変換する bookmarklet
[2006-02-11-1] bloglines のアイテムをまとめて ChangeLog メモに変換する bookmarklet
2006-02-16 Thu
2006-02-11 Sat
* bloglines のアイテムをまとめて ChangeLog メモに変換する bookmarklet [logging][firefox][bl2clog][bloglines] 10 users
新しくなりました.こちらへ [2006-10-08-3].
bloglines で開いているフィードのアイテムをごっそり ChangeLog 形式に変換して,クリップボードへコピーする bookmarklet を書いてみた.ただし firefox 専用.
-
bl2clog→ New [2006-04-22-1]→ さらにNew [2006-07-08-1]→ しつこくNew [2006-10-08-3]
書いてみたというか,下記の「ページタイトル+選択文字列+リンクを clipboardにコピーするbookmarklet」をちょっと書き換えてみただけです. bl2clog() って関数が新しいところで,他はほとんど同じ.
bl2clog() の中の clog = clog + ... のところをいじれば,違う出力フォーマットにも簡単に対応できるはず (実際,自分では ChangeLog とはちょっと違うフォーマットでメモを取っている).
JavaScript は読むことも書くこともできないので,なんか変なことやってる可能性大.実際,正規表現で力まかせに処理しているのがちょっとダサい感じ.bloglines のページ構成が変わったらアウト.もっと真面目に element や attribute を抽出するのが正しいんだろうなとか思うのだけど,まあ当面はこれでいいか.
最近は,気になったアイテムはとりあえず keep new しておいて,時間があるときにまとめて読むことが多いんだけど,ふと気づくと数十個 keep new されていて自分のメモに転記するのも億劫になってしまう(で,さらにたまる).というわけで,keep new なものをまとめて自分メモに変換する手段が欲しかった.
ついでに keep new の一斉解除もできるといいんだけど,どうすればいいのかな… (追記: できました [2006-07-08-1])
(追記) Firefox 1.5.0.1 だと動かないようです [2006-03-08-2].付け焼き刃なのでどこをどう直せばよいのかさっぱり分かりません…
(追記) Firefox 1.5.0.2 だと普通に動くようです [2006-04-22-1].なんだかさっぱり分かりません.
[2006-07-08-1] bloglines の keep new をまとめて解除する bookmarklet
[2006-04-22-1] (改版) bloglines のアイテムをまとめて ChangeLog メモに変換する bookmarklet
[2006-03-08-2] Firefox 1.5.0.1 にしてみたら
* [online pharmacy] food allergy rash hair transplant surgeo... (2019-02-27 08:11:26)
* [Consuelo Hornibrook] Hello, it\'s Consuelo here!I\'m pinging ... (2019-02-20 13:05:58)
* [Manueltak] [url=http... (2019-02-20 10:36:13)
* [JesusAvemn] [url=http... (2019-02-20 00:53:25)
* [asiameewz] amazon online and as a result Flipkart i... (2019-02-19 18:32:43)
* ...
2006-01-05 Thu
* lightbox.js [tech][firefox]
- http://openstratus.com/article/52/lightboxjs-web20/
- (via http://nais.to/~yto/clog/2006-01-04-2.html)
わー,これいい.何がいいって,JavaScript が使えなくてもちゃんと画像にアクセスできるのがすばらしい.
と思ったけど,firefox で見える場合と見えない場合があるな (PC によって違う).何が違うんだろう…と思って調べると,ツール - オプション - Web 機能 - JavaScript の詳細設定で,「画像を別のものに置き換える」がオフになっていた.まあこれオフになっていると Google Maps も動かないしな.許容範囲内か.(ちなみに firefox 1.5 には,そもそもこのオプションがないらしい.入れ換えようか)
あとこれって,あまり大きな絵が開くと,戻るときに反射的に Back の操作をして前のページに戻ってしまうところがちとアレかな,とか思ってみたり. JavaScript で Back をフックしたりとかできないのかな.
2005-11-26 Sat
2005-09-29 Thu
* pukiwiki からローカルなファイルにリンクを張る [tech][firefox] 1 user
個人用とか,組織内用とかにローカルな pukiwiki を動かしといて,そこからローカルな (あるいはイントラネット内の) ファイルを参照したいときがある.
のだが,pukiwiki は http(s) と ftp と news しか自動リンクしてくれないようだ.しかたないので力技発動.
lib/func.php と lib/make_link.php の中に数ヶ所
https?|ftp|news
なところがあるので,ここに file をがしがし付け加えていく
https?|ftp|news|file
これで
file://fileserver/sharename/
みたいのにリンクを張ってくれるようになってくれて幸せ.
ただし,firefox はローカルなファイルは開いてくれない.拡張機能の ieview 辺りを入れておくとよいようだ.
2005-07-08 Fri
* firefox 用の google toolbar [tech][firefox]
本家登場.でも結構 googlebar で満足しちゃってるんだよなあ.
* [Brettbig] wh0cd744306 <a href=http... (2017-08-05 11:47:58)
2005-03-22 Tue
2005-01-25 Tue
2004-12-12 Sun
2004-12-05 Sun
最終更新時間: 2012-02-06 01:55
Shingo W. Kagami - swk(at)kagami.org
* [asiameljp] 47ca05e6209a317a8fb3 uare you willing to... (2019-02-20 13:45:16)
* [Uqvrgtqp] Un joueur qui a lui-m??me d??shonor?? su... (2019-01-16 08:12:06)
* [Aoakiblp] Vous ne voulez ??videmment pas porter la... (2019-01-12 00:11:54)
* [Fyrurodw] Le Air Jordan Retro 6 \'Slam Dunk\' sera... (2019-01-11 20:18:54)
* [jemiamacede] Cheap MBT shoes suit for this folks,whit... (2019-01-07 11:35:43)
* ...